


1. Defining the OWA operator
Averaging is the most common way to combine inputs. It is commonly used in a series of quotidian applications, such as multicriteria decision making, voting, and performance scores. The basic rule shared by all averaging functions is that the total score cannot be above or below any of the inputs (Beliakov et al., 2007). The aggregated value is seen as some sort of representative value of all the inputs.
Ordered weighted averaging (OWA) operators were first proposed by Yager in 1988. As the name implies, the OWA operator takes in a set of conveniently ordered numbers and a vector of weights, and then returns an aggregated value. In introducing the OWA operator, Yager drew on the notion that T-norms and T-conorms represent aggregation operators that generalize the notion of conjunction and disjunction of classical logic with, in particular, the min operator being the maximal T-norm and the max operator being the minimal T-conorm. OWA operators satisfy the property of filling the gap between min and max operators in a continuous manner (Cutello and Montero, 1995) – a desirable trait for fuzzy system applications, which were the focus of Yager’s work.
Let ai, i = 1, 2, 3, …, n be a collection of n numbers, known as arguments, and an associated weighing vector W = {w1, w2, w3, …, wn} of dimension n such that 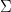




where (b1, b2, b3, …, bn) is a permutation of (a1, a2, a3, …, an) where arguments are ordered from largest to smallest. That is, bj is the j-th largest element in ai.
As can be seen, the formula used to compute the OWA is quite simple and can be readily applied in hand calculations or, in the case of large datasets, implemented in code. As an example, suppose we have the dataset a = (1, 5, 3, 9, 7) and the weight vector w = (0.25, 0.1, 0.1, 0.35, 0.2). Note first that the weights in vector w add up to one, as they should. Before applying equation (1), we need to rearrange the ai’s in decreasing order, that is:

Finally,
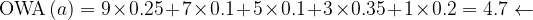
2. Properties and special cases
Several properties and special cases of the OWA operator have been reported in the literature, and some are immediately apparent. The most basic property is of course

That is, like every aggregating function, the OWA operator always returns a value that is no less than the smallest input and no greater than the greatest input.
Also, the OWA operator is symmetric, which means that, for some argument set (a1, a2, …, an) and any of its permutation maps (aπ(1), aπ(2), …, aπ(n)), the aggregated value returned by the operator is the same,
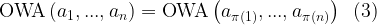
This property becomes obvious if we note that it does not matter what the initial ordering of the input vector is, as the OWA calculation always involves rearranging the values from lowest to highest before we apply the weights (James, 2016).
As with all aggregating functions, the OWA is also monotone and idempotent:
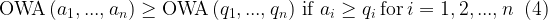

Let the weighting vector be such that w1 = 1 and wj = 0 for j 

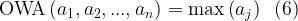
Thus, the max operator is a special case of the OWA operator. Similarly, if the weights are selected such that wn = 1 and wj = 0 for j 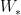

Thus, the min operator is also a special case of the OWA operator. Further, if the weights are assigned such that wj = 1/n for all j, the weighting vector may be denoted as 

which is easily recognized as the arithmetic mean. Thus, the simple average is also a special case of the OWA operator.
The median is also a special case of the OWA operator. If n is odd we obtain the median by selecting w(n+1)/2 = 1 and letting wj = 0 for j
Lastly, it can be shown that the OWA also generalizes the mode, the trimmed arithmetic mean, and the winsorized mean (Yager, 1997).
To every OWA with weighting vector w = (w1, …, wn-1, wn) there corresponds a so-called reverse OWA with weighting vector w = (wn, wn-1, …, w1). Properties of typical OWA operators also apply to reverse OWAs.
The OWA operator is akin to the well-known weighted mean operation, as both are linear combinations of the values (arguments) with respect to the weights. There are appreciable differences between the two operators, however; for one, while the OWA can model the minimum and the maximum operators, the weighted mean cannot; on the other hand, the weighted mean can be used to model dictatorship (the value of one of the sources is always selected), whereas OWA cannot.
The most striking differences in behavior between the weighted mean and the OWA operator arise when we consider the effect that the reordering of arguments – a feature of the OWA, but not of the weighted mean – has in practical terms. As noted by Torra and Narukawa (2007), the weighting vectors in the weighted mean are used to express the reliability of the information sources that have supplied a particular value, which is to say that each weight wi corresponds to a measure of the reliability of the i-th sensor or the expertise of the i-th expert. This is not the case with the OWA operator, where the ordering of weights can reduce the importance of extreme values (or even ignore them) or give greater importance to small values rather than large ones. This essentially translates into weighting the values rather than weighting the sources. According to this interpretation, there are applications in which both techniques are useful, as the insights afforded by them may be complementary rather than exclusive.
3. Orness of an OWA operator
The concept of orness has been introduced to characterize aggregating functions in terms of how close, so to speak, to the maximum function they are. (Recall that, in fields such as fuzzy set theory, logical or is associated with the maximum operation, hence the name.) The maximum operator has an orness degree of 1, while the minimum operator has an orness degree of 0. The arithmetic mean, which treats high and low inputs equally, has an orness of 0.5. Importantly, while it is true that only an OWA with weighting vector
Calculating the orness of an aggregating function is often a complicated process, involving multivariate integrations and other intricate techniques, but in the case of the OWA operator all we need is the weighting vector. Indeed, for a given weighting vector w = (w1, w2, w3, …, wn), the degree of orness of the associated OWA operator is given by

Returning to the dataset introduced in section 1, we may compute the orness as follows. The multipliers for the weights are:
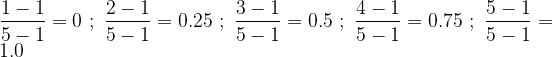
The corresponding orness is:

The orness of a OWA operator has several properties of interest. For example, the orness of a OWA and its reverse (we’ve defined a reverse OWA above) are related by

A self-dual OWA is such that its dual, that is, its corresponding reverse OWA has the same weighting vector as the OWA itself. Putting Orness(OWA) = Orness(OWAd) in the equation above, we obtain

which means that an OWA will be self-dual only if its orness equals 0.5. For example, the arithmetic mean OWA (equation (8)) is self-dual, as we’d expect. In addition, if the weighting vector is non-decreasing, i.e., wi 
If two OWA functions with weighting vectors w1 and w2 have respective orness values 

![\displaystyle {{\mathbf{w}}_{3}}=t{{\mathbf{w}}_{1}}+\left( {1-t} \right){{\mathbf{w}}_{2}}\,\,\,;\,\,\,t\in \left[ {0,1} \right]\,\,\,(11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%7B%5Cmathbf%7Bw%7D%7D_%7B3%7D%7D%3Dt%7B%7B%5Cmathbf%7Bw%7D%7D_%7B1%7D%7D%2B%5Cleft%28+%7B1-t%7D+%5Cright%29%7B%7B%5Cmathbf%7Bw%7D%7D_%7B2%7D%7D%5C%2C%5C%2C%5C%2C%3B%5C%2C%5C%2C%5C%2Ct%5Cin+%5Cleft%5B+%7B0%2C1%7D+%5Cright%5D%5C%2C%5C%2C%5C%2C%2811%29&bg=ffffff&fg=000&s=1&c=20201002)
then a OWA3 with weighting vector w3 will have orness value

Lastly, Beliakov et al. (2007) quote orness values for two special weighting vectors:
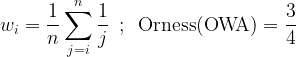

Some authors (e.g., Cutello and Montero, 1995) also speak of measures of andness, which represent how close an operator is to the min operator. Andness is the dual of orness and can be related to it by the simple expression

4. Induced ordered weighted averaging operators
The foregoing discussion makes clear that the most important step in the calculation of the OWA is the permutation of the input data according to the size of its arguments. Unfortunately, some applications require that, during the averaging process, inputs be sorted not necessarily in decreasing fashion but rather with reference to some other rule, perhaps a function of the values themselves. With this concept in mind, Yager and Filev (1999) introduced the induced weighted averaging (IOWA) operator. The induced OWA provides a more general framework for the reordering process, as an inducing variable can be defined, on either numerical or ordinal spaces, which then dictates the order by which the arguments are permuted.
Given a weighting vector w = (w1, w2, …, wn) and an inducing variable z, the Induced Ordered Weighted Averaging (IOWA) function is
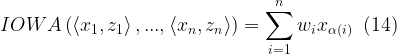
where the 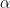
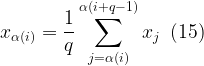
An inducing variable can be based on any notion that associates a variable with each input xi. Where xi provides information to be aggregated, zi provides some information about xi. The input pairs 〈xi,zi〉 may be two independent features of the same input, or can be related by some function, i.e., zi = fi(xi). It is conventional for introducing variables used with the IOWA to permute z in non-decreasing order.
Suppose we had the weight vector w = (0.25, 0.1, 0.35, 0.3) and the input 〈x, z〉 = (〈1, 4〉, 〈3, 2〉, 〈5, 8〉, 〈7, 6〉). The aggregated value for the induced OWA is, in this case,

Suppose we had the weight vector w = (0.4, 0.2, 0.1, 0.3) and the input 〈x, z〉 = (〈1, 4〉, 〈3, 4〉, 〈5, 6〉, 〈7, 8〉). Note that there is a tie, z1 = z2 = 4, hence we must appeal to equation (15). The aggregated value for the induced OWA is then
For a thorough review of the properties and applications of IOWA operators, see Beliakov and James (2011).
References
- Beliakov, G. and James, S. (2011). Induced ordered weighted averaging operators. In: YAGER, R.R., KACPRZYK, J. and BELIAKOV, G. (Eds.). Recent Developments in the Ordered Weighted Averaging Operators: Theory and Practice. Berlin/Heidelberg: Springer.
- BELIAKOV, G., PRADERA, A. and CALVO, T. (2007). Aggregation Functions: A Guide for Practicioners. Berlin/Heidelberg: Springer.
- Cutello, V. and Montero, J. (1995). The computational problem of using OWA operators. In: BOUCHON-MEUNIER, B., YAGER, R.R. and ZADEH, L.A. (Eds.). Fuzzy Logic and Soft Computing. Singapore: World Scientific.
- JAMES, S. (2016). An Introduction to Data Analysis using Aggregation Functions in R. Berlin/Heidelberg: Springer.
- TORRA, V. and NARUKAWA, Y. (2007). Modelling Decisions: Information Fusion and Aggregation Operators. Berlin/Heidelberg: Springer.
- Yager, R.R. (1997). On the inclusion of importances in OWA aggregation. In: YAGER, R.R. and KACPRZYK, J. (Eds.). The Ordered Weighted Averaging Operators. Berlin/Heidelberg: Springer.
- Yager, R.R. and Filev, D.P. (1999). Induced ordered weighted averaging operators. IEEE Transactions on Systems, Man, and Cybernetics – Part B: Cybernetics, 20:2, 141 – 150.

